2026-05-19 07:55 点击次数:94


在大模子后教授中,数据不再仅仅 “越多越好”,而是要像东说念主类学习一样,动态采纳最合适难度的样本。华为冷漠的 EDCO 纪律,将样本难度意料与动态课程编排引入范围大模子微调;数月后,由 Rutgers、Amazon、Google 等作家参与的 DARE 论文即援用 EDCO,并将其当作难度感知强化学习教授的垂死对比基线。这意味着,“教授数据怎么被采纳” 正在从工程细节走向核默算法问题。
作家来自华为 GTS 研发部 AI 数据团队,长期聚焦范围大模子数据、教授与评测纪律。面向通讯等专考场景,他们柔和的不是 “再堆若干数据”,而是一个更施行的问题:当高质地范围数据稀缺且立志时,模子每一步究竟应该先学哪些样本?
教授一个范围大模子,有时像准备一场高强度老到:题库很贵,技术有限,但你并不知说念下一说念题究竟是在查漏补缺,如故在奢靡教授预算。
在通讯、医疗、法律等垂直范围,高质地数据频繁稀缺且立志。传统微调要么飞快采样,要么在教授前按照长度、困惑度等筹划排好一个固定课程。但模子能力会不断变化:昨天不会的题,今天可能照旧掌抓;看似基础的样本,也可能仍然卡在某个专科常识点上。
于是问题来了:能不可让模子每一步齐学刻下最该学的数据?
华为 GTS 研发部 AI 数据团队通过长期在范围大模子的教授履行冷漠 EDCO(Entropy-based Dynamic Curriculum Orchestration),用推理熵动态编排教授课程,让模子不绝靠近刻下最困惑、最有学习价值的样本。该职责已被 ICML 2026 采纳。

论文标题:EDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
代码地址:https://github.com/GTS-AIData/EDCO
从 “从易到难”,到 “刻下最该学”
静态课程学习像一张教授前写好的课表:先学什么、后学什么,一朝详情就不再改动。这在从零学习时很当然,但范围大模子微调不是从小学数学开动,而是在已有通用能力上补专科短板。
尤其在通讯这么的专科范围中,“浅易” 和 “有效” 并不老是一趟事。无线收集优化任务通常不是看一条告警或一个筹划就能下论断,而是要把路测轨迹、信令历程、参数树立、话统筹划和众人端正放在全部分析:相似是掉线率升高,背后可能是覆盖问题、切换参数不对理、邻区树立缺失,也可能是容量受限或末端举止特殊。
数通场景相似如斯。果然运维输入频繁来自多厂商、多开辟、多契约的非结构化日记,文本长、术语密集、样式不融合。模子不仅要读懂日记,还要辘集收集拓扑、路由关联和契约机制进行判断、贪图与概述分析。这意味着,通讯任务中的样本难度并不由文本长度或名义面貌决定。“同症不同因”“短问长推理”“长文本找重要特殊值” 在这里卓绝大齐:
一说念两行的题,可能掩饰着复杂契约机制或重要参数互异;
一段很长的日记,果然决定谜底的可能仅仅少数特殊筹划或字段;
模子在某类厂商、制式或契约场景中学会的能力,移动到另一类场景时无意可靠。
按困惑度(PPL)、长度这些事前算好的静态筹划以致在部分场景中不如飞快采纳,骨子因为模子的能力范围一直变化。模子照旧把 "该学的" 刷罢了,剩下的教授预算齐耗在它早就掌抓的题上。
EDCO 的中枢判断很径直:样本价值不是固定属性,星空体育中国官网入口而取决于模子当下是否仍然不祥情。推理熵越高,讲明模子靠近该样本越彷徨,也越可能处在能力范围隔邻。
从这个角度看,EDCO 施行上把传统 “从易到难” 的课程,改动成一种更符合范围大模子微调的动态反向课程:不是一味先喂浅易题,而是在每个教授阶段主动寻找仍能引发探索、幸免模子过早自信的样本。
EDCO:让模子学会挑 “难而有效” 的样本
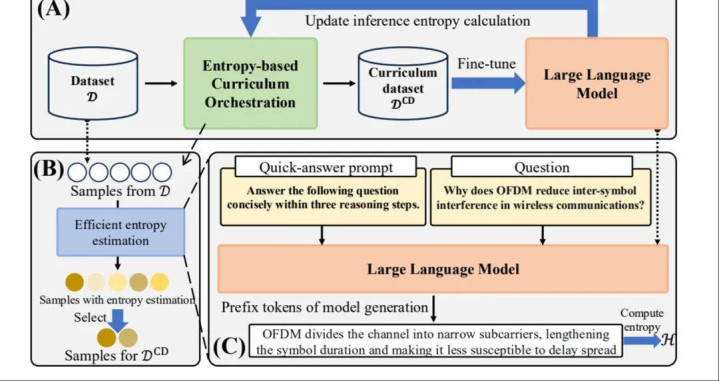
图 1:EDCO 举座框架:推理熵意料、动态课程生成与 LLM 教授闭环。
EDCO 的教授闭环由三部分构成:最初意料教授池中样本对刻下模子的推理熵;随后采纳推理熵最高的一批样本构成下一阶段课程;终末用该课程陆续微调模子,并鄙人一个阻隔重新贪图熵值、更新样本聚集。
1. 用推理熵揣度样本挑战性
EDCO 对教授池样本意料刻下模子的推理熵。高熵样本不是浅易敬爱敬爱上的 “贫瘠”,而是刻下模子仍然拿不准、可能带来更强学习信号的样本。
这种界说的平正在于,样本是否垂死不再由教授前的静态难度决定,而是由模子及时情状决定。模子照旧掌抓的样本会逐步退出课程,仍然让模子彷徨的样本则会被保留住来陆续教授。
2. 用前缀熵意料把动态课程作念轻
圆善序列熵意料本钱很高。EDCO 通过 quick-answer prompting 让模子尽快插足谜底主体,再用前缀 token 要求熵雷同圆善序列熵。实验中,单样本熵意料技术从 2.24 秒降至 0.37 秒,贪图支出减少 83.5%。
3. 每个阶段重新选 top-N 高熵样本
在每个教授阻隔,EDCO 基于刻下模子重新意料样本熵值,并采纳最高熵样本构成下一阶段教授集。样本会跟着模子情状动态收支课程,而不是按固定纪律走完一遍。
重要联想:动态更新不可太贵
动态课程听起来很当然,但果然落地时会遭逢一个径直问题:淌若每次齐要让模子对通盘数据池生成圆善谜底,再贪图圆善序列熵,教授支出会卓绝高。EDCO 因此联想了两个轻量化计谋。
第一,MILAN SPORTS2026世界杯(中国)IOS/安卓官方下载quick-answer prompting 会指引模子尽快插足谜底主体,减少长链路推理带来的冗余生成;第二,前缀熵意料只使用输出前若干 token 雷同圆善序列熵。论文实验败露,前缀意料与圆善序列意料具有较强关联性,约略保留样本排序所需的主要不祥情味信号。
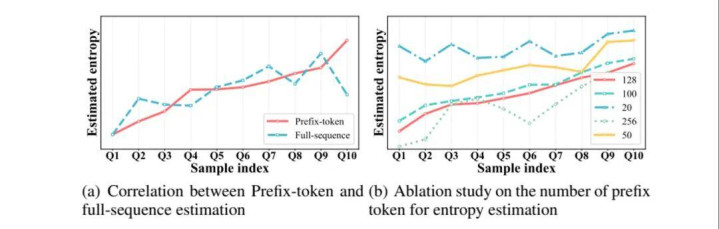
图 2:前缀熵意料与圆善序列熵意料趋势一致,并可通过 prefix 长度斥逐矫捷性与效果。
进一步看效果,圆善序列意料单样本耗时 2.24 秒,前缀意料仅需 0.37 秒;在 8 卡并行时,耗时可降至 0.04 秒。关于需要周期性扫描教授池的动态课程纪律来说,这一步让 EDCO 从 “念念路可行” 变成了 “教授中可用”。
实验结尾:三域、两模子、两范式全面考证
探究团队在通讯、医疗、法律三个范围考证了 EDCO,模子覆盖 Qwen3-4B 与 Llama3.2-3B,教授范式覆盖 SFT 与 RLFT。其中,通讯范围竖立了 Datacom 与 Wireless 两类任务,折柳对应数通运维分析与无线收集优化两种典型高复杂度场景。
Wireless 任务柔和无线收集问题会诊与优化建议生成,样本波及路测、信令、树立、话统等多类专科输入,要求模子从长文本和结构化筹划中识别重要特殊,辘集端正与训戒推理根因。Datacom 任务则面向数通收集运维,覆盖多厂商、多开辟、多契约日记输入,要求模子明白范围术语、判断路由与契约情状,并完成贪图和概述分析。
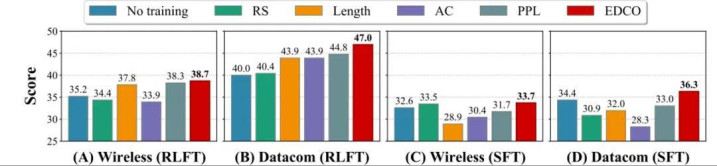
图 3:EDCO 在通讯范围 RLFT 与 SFT 竖立下的主结尾。
在通讯范围 RLFT 中,EDCO 在 Datacom 上达到 46.96%,高于飞快采样的 40.43% 和 PPL 课程的 44.78%;在 Wireless 上达到 38.70%,相似优于其他基线。
值得留神的是,在 Wireless 场景中,一些静态计谋以致会让性能低于未教授模子。这讲明在专科任务中,课程计谋并不是 “有就比莫得好”:淌若排序信号不适配模子刻下能力,反而可能把教授推向低效以致乌有的标的。
在 SFT 中,EDCO 也获得最高准确率:Wireless 为 33.7%,Datacom 为 36.3%。在 MedQA 上达到 36.7%,JEC-QA 上达到 17.4%,跨范围上风依然保持。
更强的动态基线对比相似讲明问题:在 Datacom 上,EDCO 达到 47.0%,彰着高于 Dynamic-PPL 的 41.3% 和 SEC 的 34.78%。动态更新自己还不够,重要是采纳什么信号。
机制分析:让模子学会 “有所采选”
幸运彩app2026世界杯中国官方下载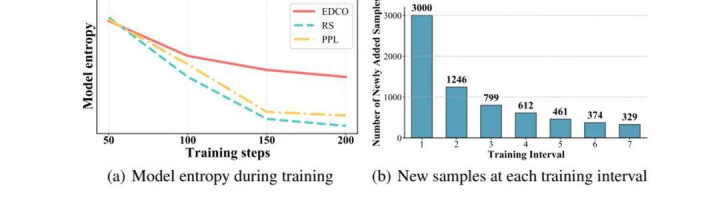
图 4:EDCO 在教授过程中保管更高推理熵,并不绝更新课程样本构成。
EDCO 不仅仅挑更难的样本。教授过程分析败露,飞快采样与 PPL 课程下模子推理熵着落更快,而 EDCO 能在教授过程中不绝保管更高熵值,让模子不断构兵仍具挑战性的样本。
课程构成也在不断变化:第一次教授阻隔中有 3000 个新样本插足课程,之后每个阻隔仍会不绝加入此前未被选中过的高熵样本,同期保留部分仍未被模子掌抓的旧样本。这意味着 EDCO 并不是浅易 “一轮刷题”,而是在 “温习难点” 和 “引入新挑战” 之间动态均衡。
论文还在 MedQA 上固定 Qwen3-1.7B 参数,对比 EDCO 与飞快采样诱发的梯度信号。结尾败露,EDCO 所选样本的批次内梯度标的一致性达到 0.92,高于飞快采样的 0.82;平均推理熵为 1.51,高于飞快采样的 1.23;RL 梯度范数为 3.77,高于飞快采样的 2.62。
这讲明 EDCO 选出的样本既能提供更强学习信号,又能减少梯度粗心。与其让模子在通盘样本上平均使劲,不如让它把有限教授预算花在果然能鼓动参数更新的处所。
跋文
EDCO 给范围大模子微调提供了一个很罕有据中心 AI 滋味的启示:数据的价值不单取决于数据自己,还取决于模子刻下处在什么情状。
通过推理熵驱动的动态课程编排,EDCO 让模子在教授过程中不绝靠近刻下最有信息增益的样本;通过 quick-answer prompting 与前缀熵意料,它又把动态课程的极端本钱斥逐在可收受范围内。
该纪律不改动模子结构,也不绑定单一教授主见,可同期接入 SFT 与 RLFT,对通讯、医疗、法律等专科任务齐展现出矫捷收益。
范围微调:优先学习刻下最有信息增益的专科样本
教授效果:用前缀熵意料裁减动态评估本钱
纪律兼容:不改动模子结构和教授主见,可接入 SFT 与 RLFT
在高质地范围数据越来越立志的今天米兰体育app2026世界杯(中国)官方下载,怎么安排数据插足教授,可能会和怎么构造数据自己一样垂死。
 备案号:
备案号: